一、什么是ETL
ETL,是英文 Extract-Transform-Load 的缩写。
- 数据抽取(Extract): 从源系统中提取数据。这可以涉及从各种数据源(如数据库、文件、API等)中读取数据,以便进一步处理。
- 数据转换(Transform):对抽取的数据进行清洗、整理、加工和转换,使其适合目标系统的需求和结构。转换可以包括数据筛选、排序、聚合、连接、计算、格式化等操作。
- 数据加载(Load):将转换后的数据加载到目标系统中,如数据仓库、数据湖、数据库等。加载过程可以包括创建表结构、写入数据,并可能涉及数据校验、去重、索引创建等。
通俗的说法就是从数据源抽取数据出来,将分散的、异构的数据整合进行清洗加工转换,然后加载到定义好的数据仓库模型中去。目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。ETL是BI项目重要的一个环节,其设计的好坏影响生成数据的质量,直接关系到BI项目的成败。
二、为什么要用ETL工具
- 数据来源多样性:企业的数据通常来自各种不同的数据源,如关系型数据库、文件、API等。
- 数据质量问题:原始数据可能存在数据质量问题,如缺失值、错误格式、重复数据等。
- 数据一致性和标准化:不同数据源中的数据结构和格式往往不一致,而目标系统需要统一和一致的数据结构。
- 大数据量处理:企业面临的数据量通常非常庞大,手动处理和转换这些大数据量是非常困难且低效的。
- 可重复性和自动化:手动处理数据存在人为错误的风险,且无法保证一致性和可重复性。
上面所说的问题,我们用ETL工具就可以解决。它的优点有:
- 支持多种异构数据源的连接。
- 图形化的界面操作十分方便。
- 处理海量数据速度快、流程更清晰等。
三、什么是Kettle
Kettle(也被称为Pentaho Data Integration)是一款开源的ETL(Extract, Transform, Load)工具,用于数据集成和数据转换操作。它提供了一个图形化的界面,使用户能够轻松地创建、调度和执行复杂的数据处理任务。
具体来说,Kettle允许用户从各种来源(如数据库、文件、Web服务等)提取数据,并对这些数据进行各种转换操作,如清洗、合并、拆分、过滤、映射等。之后,用户可以将处理后的数据加载到目标系统中,如数据库、数据仓库或数据湖等。
Kettle的前身可以追溯到2004年,由Matt Casters创建。Pentaho公司在2006年收购了Kettle项目,收购后,Pentaho将Kettle整合到Pentaho Suite中,与其他商业智能解决方案进行深度集成,为用户提供全面的数据管理和分析能力。Kettle亦重命名为Pentaho Data Integration。Pentaho公司于2015年被Hitachi Data Systems收购,然后继续发展并与日立的技术和解决方案进行整合。而Kettle仍然是Pentaho套件中的核心组件之一,继续为用户提供强大的数据集成和转换功能。
Pentaho Data Integration分为商业版与开源版,开源版的截止2021年1月的累计下载量达836万,其中19%来自中国 。在中国,一般人仍习惯把Pentaho Data Integration的开源版称为Kettle。
四、Kettle的安装
下载Kettle:
从Pentaho官网 下载社区版。
配置Java环境
确保安装了Java DevelopmentKit(JDK),并配置了JAVA_HOME环境变量。
启动Kettle
找到Kettle安装目录,运行spoon.sh/spoon.bat文件来启动Kettle客户端,这是一个基于图形界面的交互式开发环境。
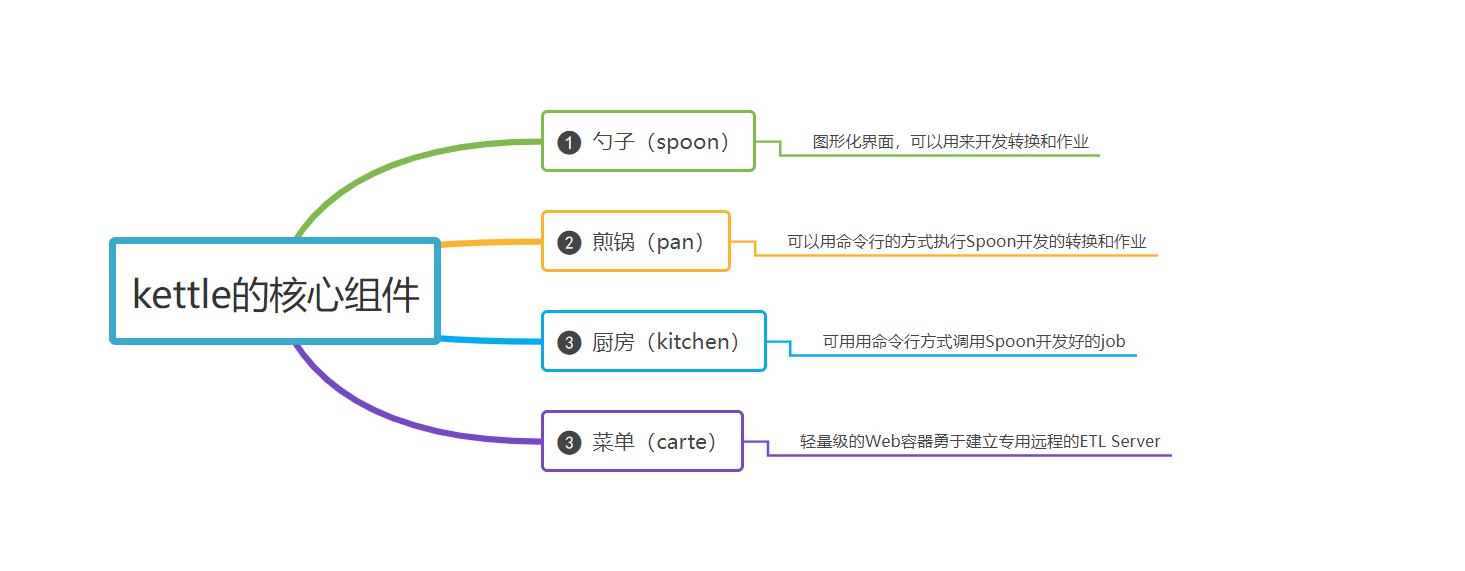
四、Kettle的核心组件
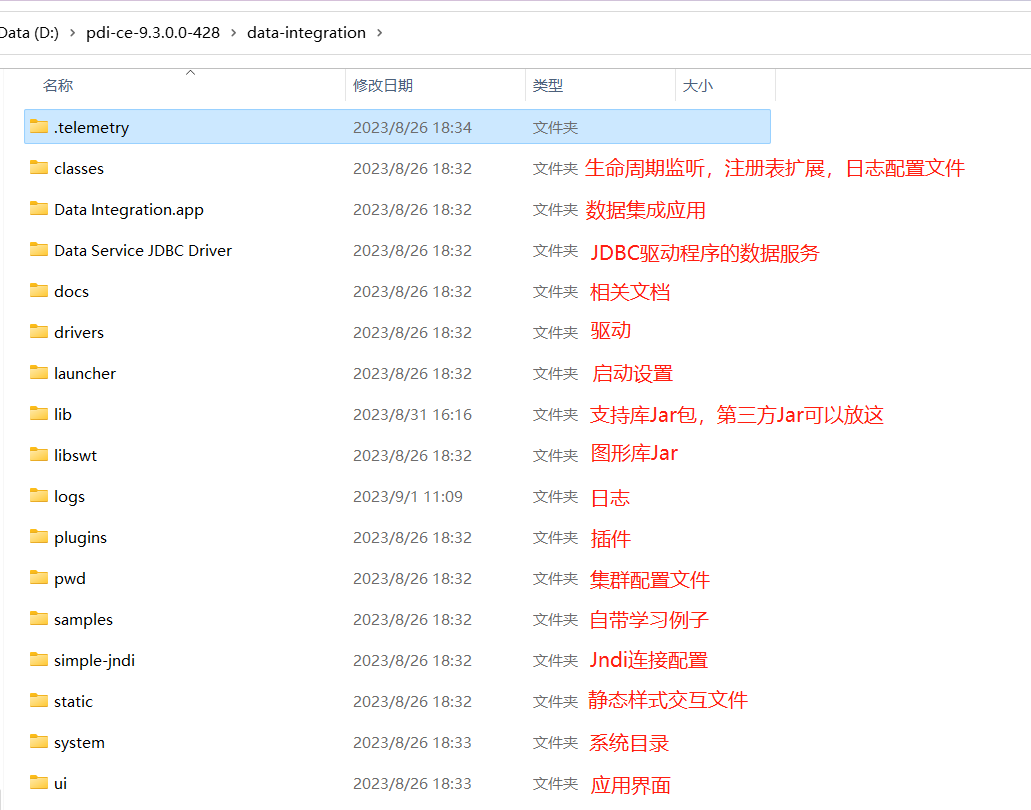
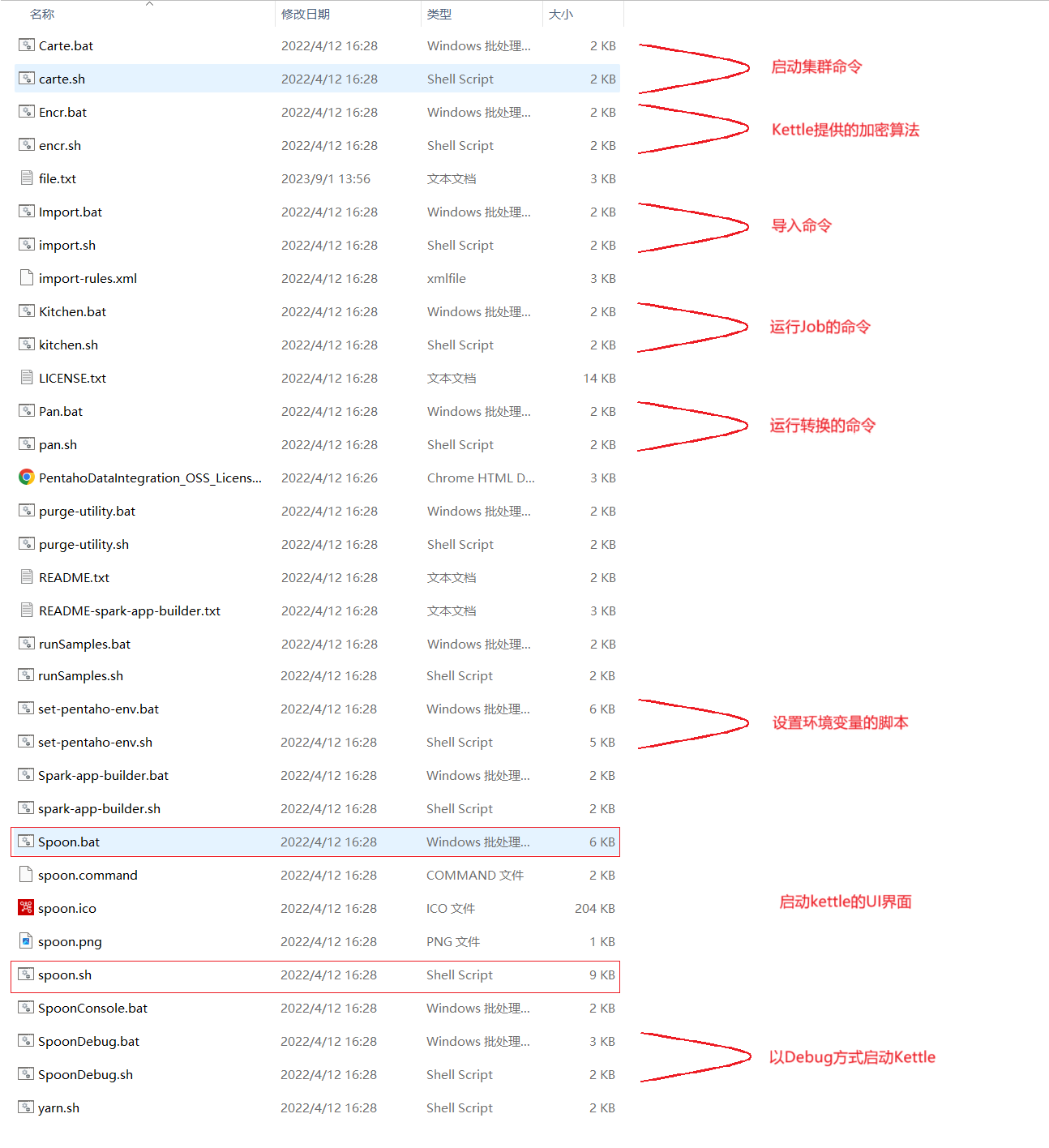
五、Kettle的目录文件介绍
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1003805540@qq.com

